From Notebook to Production: Understanding ML in Production
AuraWeb
February 18, 2026
Machine LearningProductionMLOps
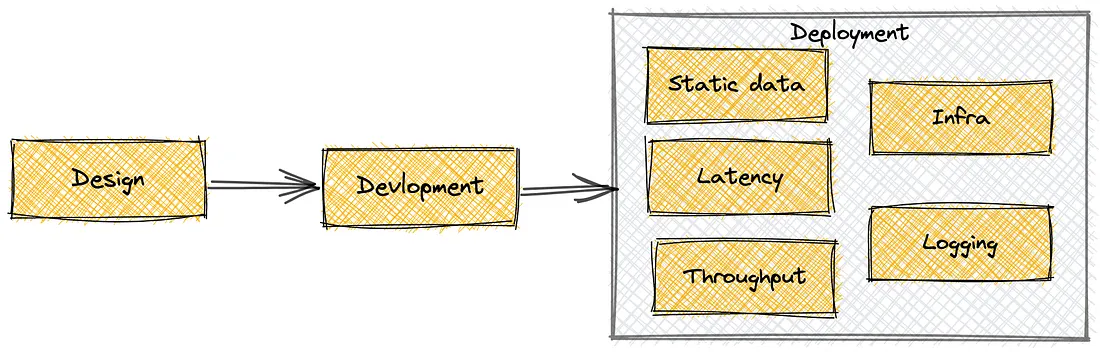
The training of models is not the end of machine learning. The reality is that training is not an end in itself. The actual complexity begins once you attempt to implement that model into a real-life system in which users are going to be interacting with the system, traffic will be changing, and data will always be changing.
Most of the ML projects fail not due to the inaccuracy of the model, but the system surrounding the model is weak. The engineering discipline, infrastructure planning and constant monitoring are necessary in production ML.